WITH stats AS ( -- 计算数据集中各个变量(降雨量、气温、pH 值、产量)的均值和标准差 SELECT AVG(Rainfall) AS mean_rainfall, -- 计算降雨量的均值 STDDEV(Rainfall) AS std_rainfall, -- 计算降雨量的标准差 AVG(Temperature) AS mean_temperature, -- 计算气温的均值 STDDEV(Temperature) AS std_temperature, -- 计算气温的标准差 AVG(Ph) AS mean_ph, -- 计算 pH 值的均值 STDDEV(Ph) AS std_ph, -- 计算 pH 值的标准差 AVG(Production) AS mean_production, -- 计算产量的均值 STDDEV(Production) AS std_production -- 计算产量的标准差 FROM crops_data ), z_scores AS ( -- 计算每个作物数据的 Z 分数(标准化分数) SELECT Crop, -- 作物名称 (Rainfall - stats.mean_rainfall) / stats.std_rainfall AS z_rainfall, -- 降雨量的 Z 分数 (Temperature - stats.mean_temperature) / stats.std_temperature AS z_temperature, -- 气温的 Z 分数 (Ph - stats.mean_ph) / stats.std_ph AS z_ph, -- pH 值的 Z 分数 (Production - stats.mean_production) / stats.std_production AS z_production -- 产量的 Z 分数 FROM crops_data, stats -- 与统计信息进行笛卡尔连接,计算标准化值 ) -- 将处理后的数据覆盖写入目标表 cleaned_crops_data INSERT OVERWRITE TABLE cleaned_crops_data SELECT* FROM crops_data WHERENOTEXISTS ( -- 排除异常值(Z 分数绝对值大于 3 的记录) SELECT1 FROM z_scores WHERE (ABS(z_rainfall) >3ORABS(z_temperature) >3ORABS(z_ph) >3ORABS(z_production) >3) -- 判断是否为异常值 AND crops_data.Crop = z_scores.Crop -- 确保作物名称匹配 );
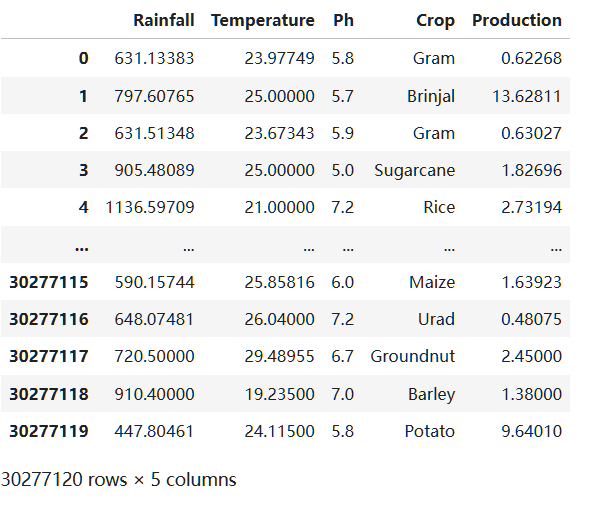
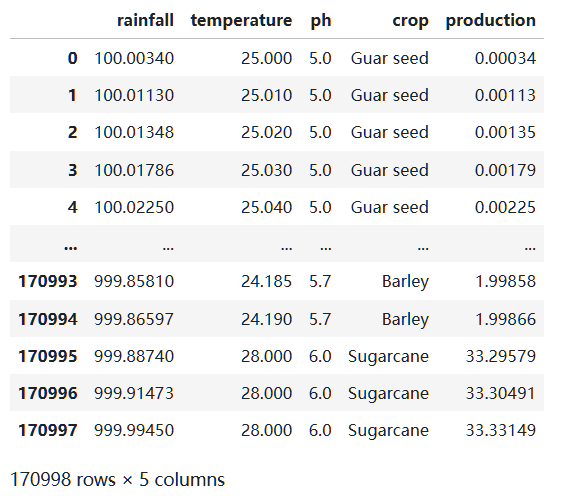
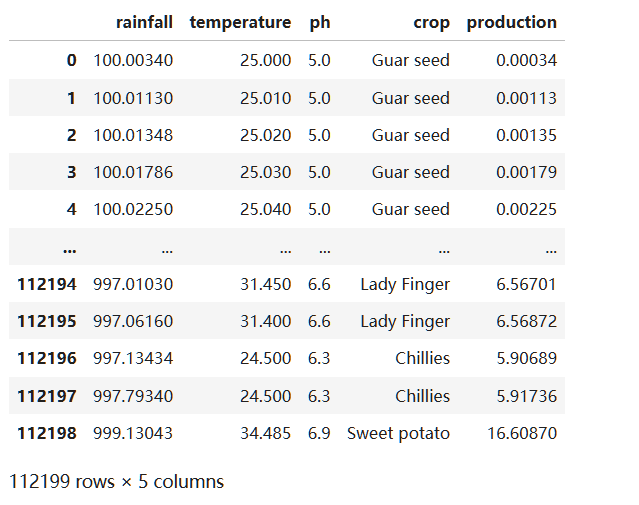
hive处理缺失值和异常值后数据
2.4. hive分析数据
1 2 3 4 5 6 7 8 9
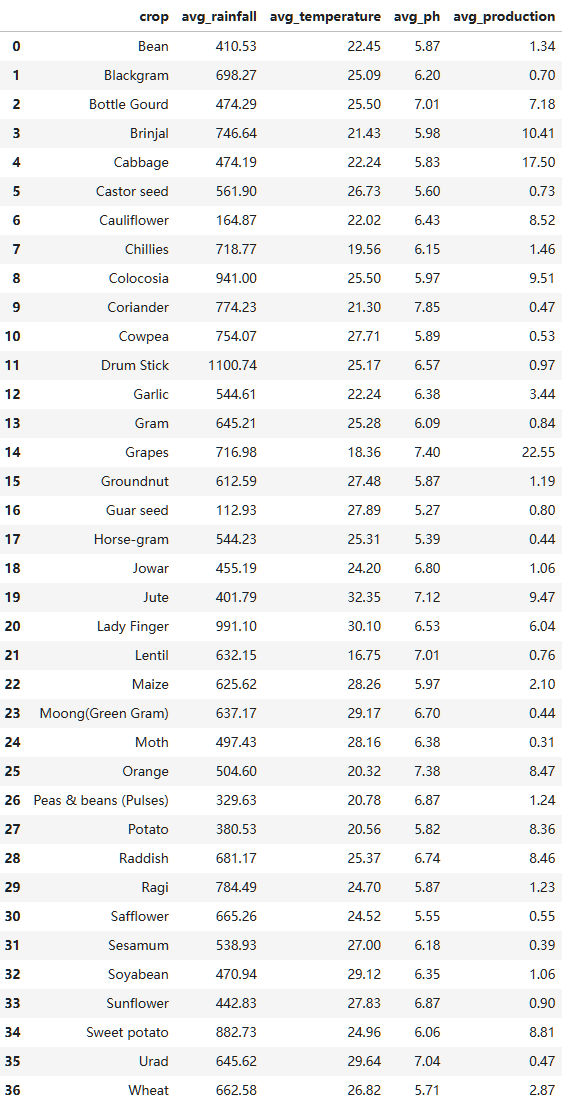
#获取作物分组后四个指标的平均值 CREATEtable avg_crops_data1 AS SELECT crop, AVG(rainfall) AS avg_rainfall, AVG(temperature) AS avg_temperature, AVG(ph) AS avg_ph, AVG(production) AS avg_production FROM cleaned_crops_data GROUPBY crop;
1 2 3 4 5 6 7 8
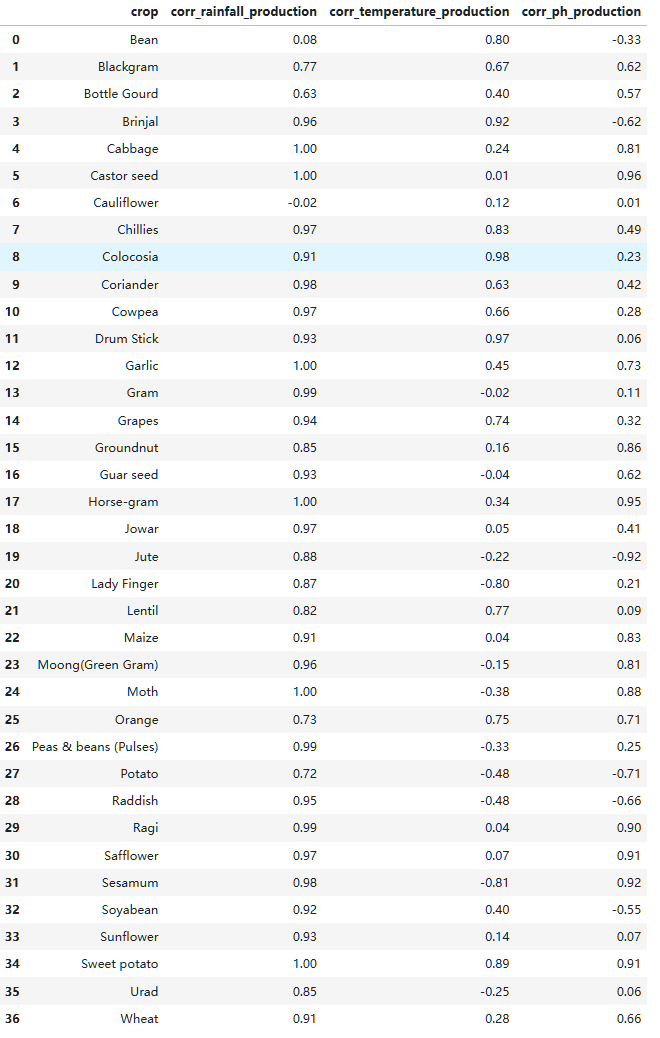
获取作物分组后三个指标与产量的相关性 CREATETABLE corr_crops_data AS SELECT crop, CORR(rainfall, production) AS corr_rainfall_production, CORR(temperature, production) AS corr_temperature_production, CORR(ph, production) AS corr_ph_production FROM cleaned_crops_data GROUPBY crop;
1 2 3 4 5 6 7 8 9 10 11 12 13
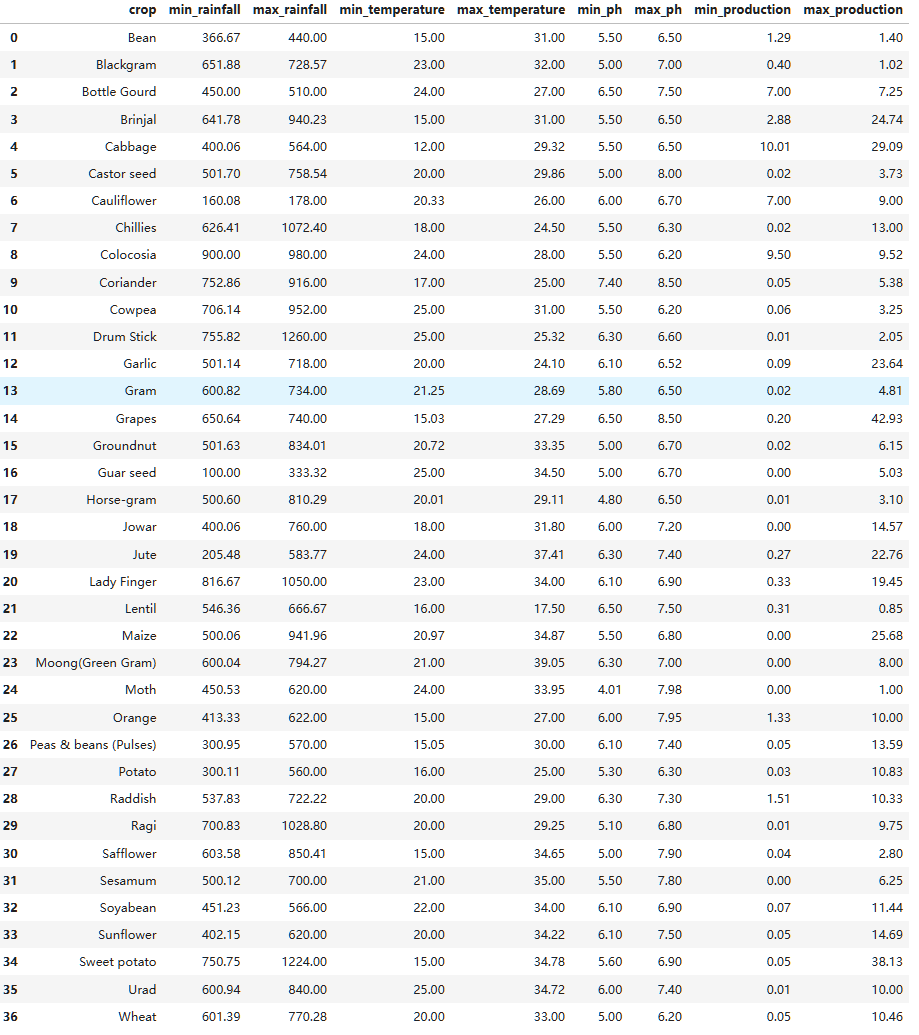
获取作物分组后四个指标的最大值和最小值 CREATETABLE extremal_crops_data AS SELECT crop, MIN(rainfall) AS min_rainfall, MAX(rainfall) AS max_rainfall, MIN(temperature) AS min_temperature, MAX(temperature) AS max_temperature, MIN(ph) AS min_ph, MAX(ph) AS max_ph, MIN(production) AS min_production, MAX(production) AS max_production FROM cleaned_crops_data GROUPBY crop;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
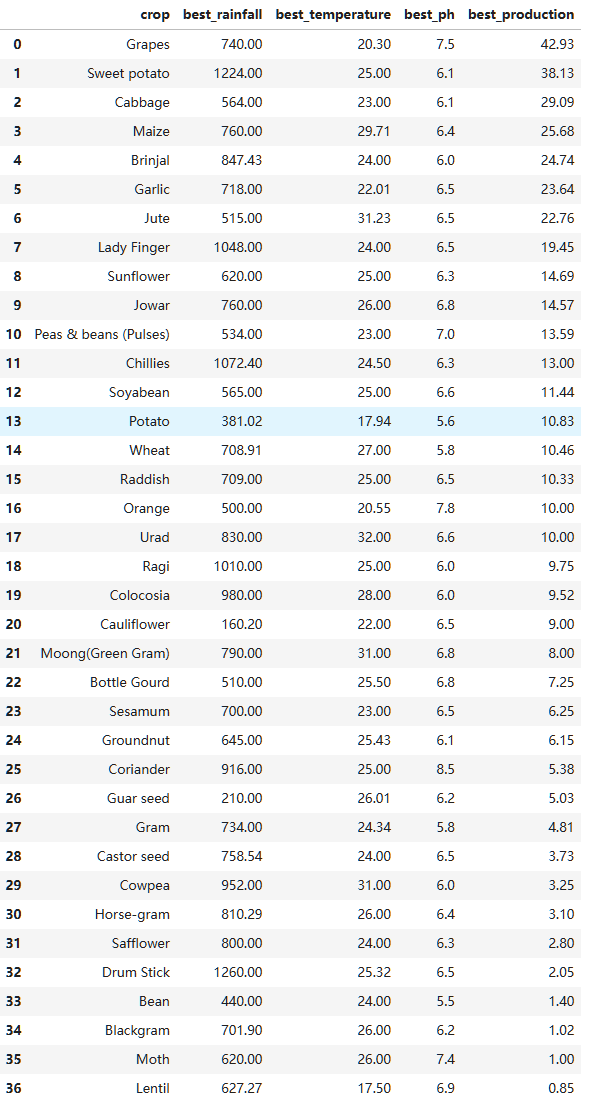
获取每个作物产量最大的一条记录然后根据作物产量全局排序: CREATETABLE best_crops_data AS SELECT crop, rainfall AS best_rainfall, temperature AS best_temperature, ph AS best_ph, production AS best_production FROM ( SELECT crop, rainfall, temperature, ph, production, ROW_NUMBER() OVER (PARTITIONBY crop ORDERBY production DESC) AS rn FROM cleaned_crops_data ) subquery WHERE rn =1 ORDERBY best_production DESC;
1 2 3 4 5 6 7 8 9
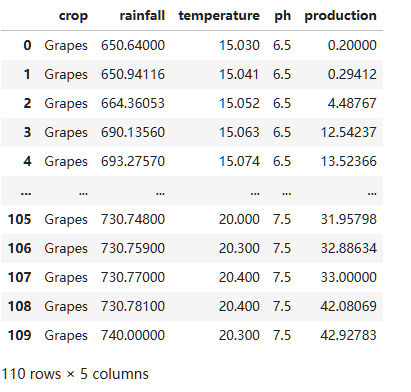
获取grapes作物环境影响情况 CREATETABLE grapes_data AS SELECT crop, rainfall, temperature, ph, production FROM cleaned_crops_data WHERE crop='Grapes';